
The Writer-Researcher’s Guide to Claude Code
How I built a full knowledge-management system, and what it unlocked.

Friends,
Sometime, about three months ago, I had a realization. It may sound obvious to many of you, and absurd to others.
It is this: the Claude models released in December (and improved upon since) have driven the greatest personal capability leap in my lifetime.
The iPhone changed the way I accessed information and navigated the world. Social networks altered how I communicated and fraternized. Any number of apps and programs improved my workflows, smoothed opportunities, and accelerated my thinking. Doubtless, dozens of quieter improvements have changed the texture of my life without me realizing it — superior medicines and more efficient machines.
But as a single, discrete jump, nothing else comes close. Before Opus 4.5 — Claude’s winter upgrade — I had opened my computer’s terminal on a handful of occasions, mostly by accident. The last time I’d actually tried to use it had been a 2015 continuing education course at General Assembly that I’d bungled through with the grace of a macaque running a printing press.
Today, I spend more than 70% of my working hours in the terminal. I build software, construct systems, and conduct sprawling research assignments. Agents parse hundreds of articles, looking for tidbits aligned with my interests or writing goals, and prepare reports in my preferred style. Others streamline administrative duties, find bugs, polish edges, and ship the next feature I have in my mind.
The result is a system that increasingly feels not just like an extra employee, but closer to 20.
One of the challenges of running a business like The Generalist is that you cannot play just one role. I may get the greatest pleasure from sitting in front of an empty screen and beginning to write, but there are bills to be paid, scheduling to do, dashboards to survey, growth strategies to deploy, sponsors to consider, and emails to send. Every day is a battle between deep work and the realities of running a business. It is an unavoidable fact that every hour spent on these things is one I cannot spend on the parts I enjoy most and where I feel I have the greatest advantage.
Even outside these especially mundane tasks, there are thousands of little irritations and distractions. Try to conduct detailed research on a person or topic, and count the moments of friction. How many paywalls will you hit for publications you already purchase? How many pop-up ads or cookie advisories? What purposefully distracting news carousel will spin across the bottom of your article? What video will stuff itself in from the side? If you want to study someone’s background on LinkedIn or Twitter, how many red notifications will raise themselves like welts? How many DMs call for your attention? What new product announcement screams for you from the feed? How many greedy fingers try to grab your focus in the simple act of trying to travel from A to B, from intent to information?
The modern internet has become an attention casino, and we have grown accustomed to working in the middle of it, averting our eyes from clanking slots and spinning wheels. But what if your workspace could feel more like a quiet desk in a well-lit library? What if you could dispatch 20 virtual employees to wade through the morass of the modern web for you and deliver the results? What if you could cut back on the logistics and wrangling and give yourself the time to focus on the one thing you do not want AI to do for you? What if you could double the time you spent in deep work?
Over the past few months, I have been using Claude Code to explore these questions for myself. The result is a full-stack knowledge management system spanning multiple software products, internal systems, and a local model. (I have built several other things, but this is the crispest distillation.) It is not perfect, nor will it be for everyone. Showing these systems to friends and family over the past months, I’ve found that it often helps people better understand what is now possible with these models, and how you might use them to your benefit.
When I’ve caught up with these people days or weeks later, I’ve often found they’ve undergone a similar transformation, from dabbler to devotee. While there’s undoubtedly a risk in outsourcing too much, including the act of thinking itself, so far I haven’t found this to be true for myself or others. Rather, people seem to be having an extremely fun time, building systems that take away drudgery and interfaces explicitly shaped for how their minds work. It’s incredible how much easier and more pleasant it is to navigate an app that intuitively works the way your brain does, rather than one constructed for the general population.
If you’re curious about these tools, I would recommend setting yourself the goal of building the smallest possible thing you can think of. You’ll quickly find your ambitions grow as your comfort sitting in front of a terminal does.
With that, here’s a look at my system and how it’s changed my workflow.
The Library
There is a particular type of cognitive annoyance which one might call “thing-finding.” You have undoubtedly experienced it. It is the moment when you’re forced to stop in the middle of something and ask, “Agh, what was that thing again? That thing that person said? That thing I read? That thing I wrote? Did I save it somewhere? Is it in Google Drive? Will Finder locate it? (Nope!)”
An occupational hazard of running a media company is that there are a lot of things. There are research things and podcast things and article things and note things and PDF things and email things and interview things. And they are invariably quite hard to find. Historically, they have been spread out across my desktop, Google, Obsidian, Ulysses, The Generalist’s website, and Dropbox. In the grand scheme of the travails of the world, the callous mysteries of the universe, dark matter, and the infinite unknown, I recognize this is not a real problem. But when you are in the middle of a piece, just beginning to find that fragile rhythm that even an ambling ice cream truck can disrupt, this is among the most annoying interruptions possible.
Delphi, the all-seeing oracle, is the solution I’ve built to address this issue.
To start, I compiled every piece The Generalist has ever written, the transcripts of every podcast I have recorded, my full compendium of Obsidian notes, my Readwise highlights, a good chunk of Google Drive, and assorted files from my desktop. In total, there are more than 45,000 searchable “chunks,” with more added by the day.
The search pipeline relies on three layers, fused together: vector search via Voyage-3 embeddings, keyword search via SQLite FTS5, and a locally trained cross-encoder reranker, distilled from Cohere. I created the reranker by starting with a compact, open-source model pre-trained on Microsoft’s MS MARCO search dataset and fine-tuning it on nearly 40K query-passage pairs from our data. That taught the model what “relevant” looks like from our initial Cohere setup, and allowed Delphi to deliver high-quality results more quickly and cheaply.
If you don’t know what this means, don’t worry. It’s absolutely not necessary to get this deep into the weeds. I certainly didn’t expect to fine-tune even a tiny model of my own, but bit by bit, you start to become interested in what else you can do. The system above is, I’m sure, far from perfect, but it’s working well for me at the moment.
Now, using Delphi, I can type in a half-formed query like “remind me what philosopher Karol talked about on the podcast,” and it will recall that Karol Hausman, CEO of Physical Intelligence, shared his interest in Spinoza.
If I want to ask something that requires referencing multiple sources—for example, what CEOs have said about their hiring practices—it can handle that too, pulling in references from across my corpus.
I could have answered these questions in the past. The first one would have taken me a few minutes of pecking and tabbing; the second perhaps several hours. In all likelihood, I simply wouldn’t have bothered.
As a destination, I don’t use Delphi that often, and I still think it can be greatly improved. The UX isn’t quite as polished as I would like, and search is good, but could still be faster and smarter. But it mostly does what I want it to, and it’s reassuring to know that it’s there when I need it. As you’ll see, its power is leveraged in our other tools.
The Researchers
The most useful thing I have built is not visible, nor easily explicable. It is a concatenation of skills, tools, techniques, and preferences that allow me to gather information widely and thoroughly, without having to do the hunting and pecking myself.
Fundamentally, my research system operates through a collection of agents dedicated to snuffling out relevant information from particular mediums. One scans my internal corpus for existing work. Another reads relevant articles. A third seeks out podcast appearances.
Like Liam Neeson’s protagonist from Taken, each of these has been equipped with a “particular set of skills” that aid them in their quest. Jina and Firecrawl turn webpages into clean, readable text. An open-source tool searches YouTube and pulls crisp transcripts of interviews. Various scripts search for a subject’s published writing (a blog or personal webpage) or secondary media appearances. A headless browser allows agents to access articles on paywalled sites for which I have subscriptions. Instead of having to check The Financial Times, The Economist, and The New Yorker one by one, the agent can do it for you, as long as you’re logged in.
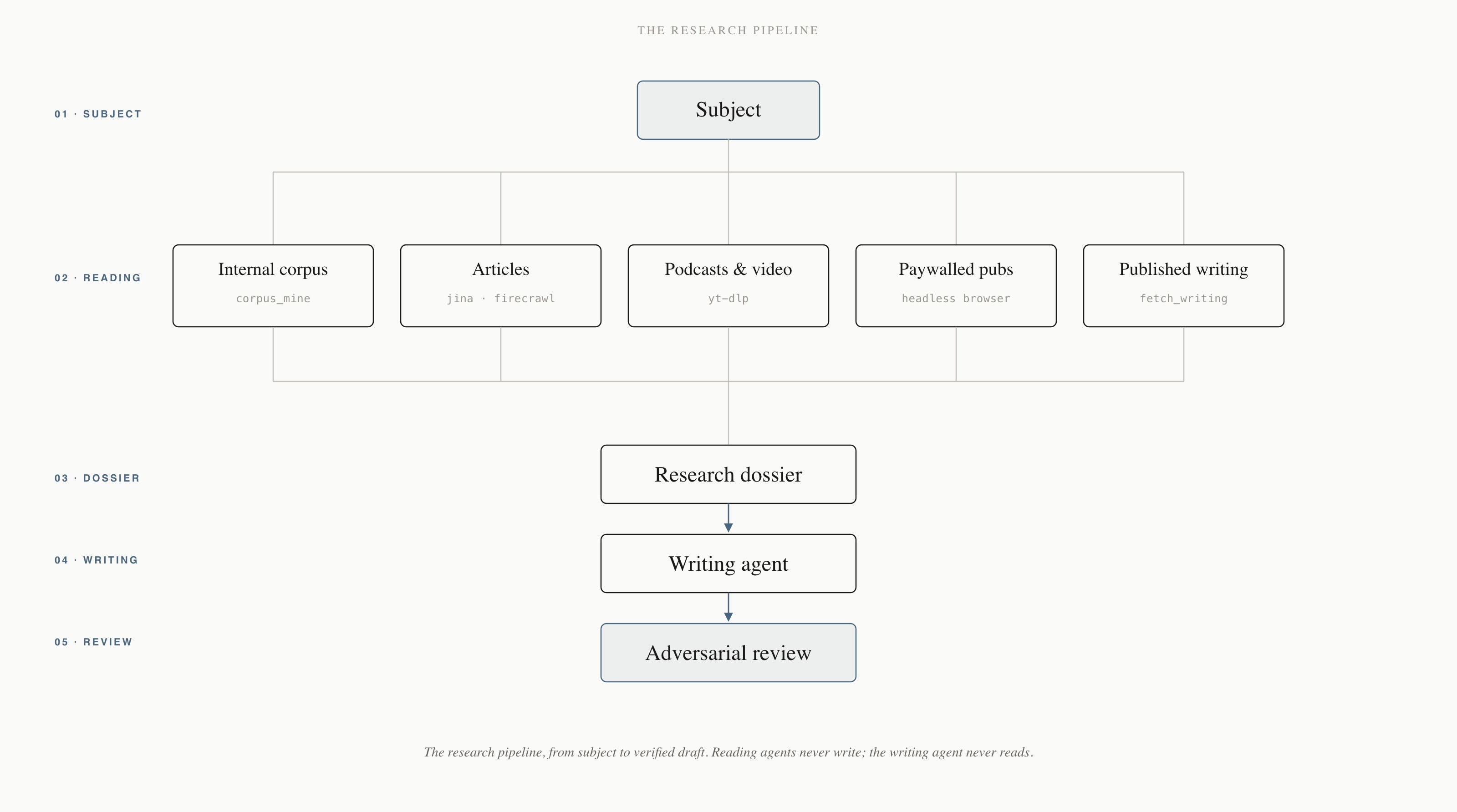
Crucially, it can do all of this in the background while you work on something else. Not only have you avoided the attention pitfalls and switching costs imposed by the modern web, but you’ve effectively hired a capable research assistant. I had always hoped The Generalist would grow large enough for it to make sense for me to hire such a person; now, I have been granted a dozen, each with a very strong grasp on what I am likely to find most relevant.
To ensure the research is conducted at a high standard, I’ve created a set of skill files for these agents to reference. These include dictums such as: